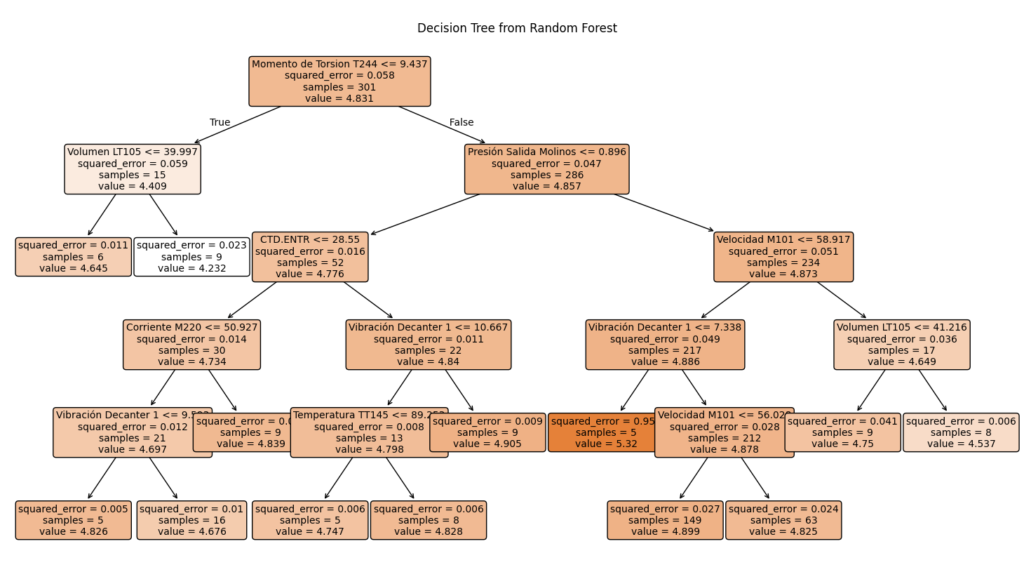
De lo simple a lo sofisticado: predicción del porcentaje de proteína del haba de soja en procesos industriales.


También te puede interesar lo siguiente

Gemelo Digital Industrial: Optimización Inteligente en la Industria 4.0
En CIVIR estamos encantados de compartir que hemos obtenido la certificación ISO 20000

CIVIR potencia la transformación digital de empresas en 2025 con consultoría IT, formación tecnológica y certificaciones IT
En CIVIR estamos encantados de compartir que hemos obtenido la certificación ISO 20000

Certificaciones CIVIR: la compañía alcanza 59 certificados en 2024
En CIVIR estamos encantados de compartir que hemos obtenido la certificación ISO 20000